This means if ShiftBounds returns [a,b] for the log-transformed samples, RatioBounds returns [ea,eb].
RatioBounds provides not just the estimated ratio but also the uncertainty of that estimate. The function returns an interval of plausible ratio values given the data. Set misrate to control how often the bounds might fail to contain the true ratio: use 10−3 for everyday analysis or 10−6 for critical decisions where errors are costly. These bounds require no assumptions about your data distribution, so they remain valid for any continuous positive measurements. If the bounds exclude 1, that suggests a reliable multiplicative difference between the two groups.
See also:Compare2 for comparing Ratio against practical thresholds with automatic verdict generation.
Algorithm
The RatioBounds estimator uses the same log-exp transformation as Ratio, delegating to ShiftBounds in log-space:
Log-transform Apply log to each element of both samples. Positivity is required so that the logarithm is defined.
Delegate to ShiftBounds Compute [a,b]=ShiftBounds(logx,logy,misrate). This provides distribution-free bounds on the shift in log-space.
Exp-transform Return [ea,eb], converting the additive bounds back to multiplicative bounds.
Because log and exp are monotone, the coverage guarantee of ShiftBounds transfers directly: the probability that the true ratio falls outside [ea,eb] equals the probability that the true log-shift falls outside [a,b], which is at most misrate.
Notes
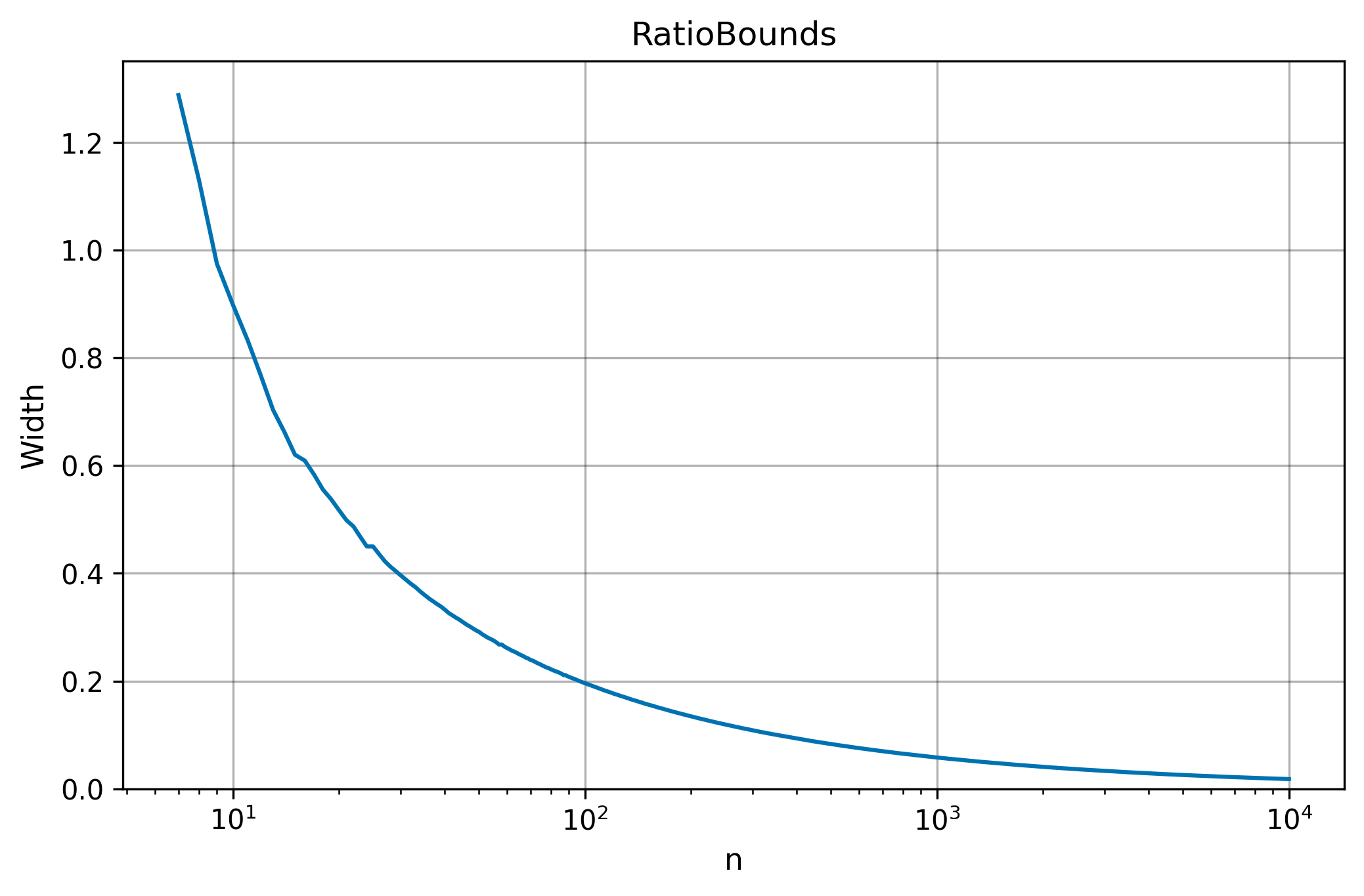
Width Convergence
The table below shows how Width=U−L narrows as N grows, for x=y=(1,1+1/(N−1),…,2) (N evenly spaced points on [1,2]) and misrate=10−3. Dashes indicate N too small to achieve the target misrate.
The RatioBounds test suite contains 63 test cases (3 demo + 9 natural + 6 property + 10 edge + 9 multiplic + 4 uniform + 5 misrate + 15 unsorted + 2 error). Since RatioBounds returns bounds rather than a point estimate, tests validate that the bounds contain Ratio(x,y) and satisfy equivariance properties. Each test case output is a JSON object with lower and upper fields representing the interval bounds. All samples must contain strictly positive values. The domain constraint misrate≥2/(nn+m) is enforced; inputs violating this return a domain error.
These cases illustrate how tighter misrates produce wider bounds and validate the identity property where identical samples yield bounds containing one.
Note: positive range [1,10) used for ratio compatibility
The asymmetric size combinations are particularly important for testing margin calculation with unbalanced samples.
Misrate variation (n=m=20, x=(1,2,…,20), y=(2,4,…,40)) — 5 tests from a loose achievable fixture misrate down to 10−6:
These tests use identical samples with varying misrates to validate the monotonicity property: smaller misrates produce wider bounds. The sequence demonstrates how bound width increases as misrate decreases, helping implementations verify correct margin calculation.
Unsorted tests — verify independent sorting of x and y (15 tests):
unsorted-x-natural-5-5: x=(5,3,1,4,2), y=(1,2,3,4,5) (X reversed, Y sorted)
unsorted-y-natural-5-5: x=(1,2,3,4,5), y=(5,3,1,4,2) (X sorted, Y reversed)
unsorted-demo-unsorted-x: x=(5,1,4,2,3), y=(2,3,4,5,6) (demo-1 X unsorted)
unsorted-demo-unsorted-y: x=(1,2,3,4,5), y=(6,2,5,3,4) (demo-1 Y unsorted)
unsorted-demo-both-unsorted: x=(4,1,5,2,3), y=(5,2,6,3,4) (demo-1 both unsorted)
unsorted-identity-unsorted: x=(4,1,5,2,3), y=(5,1,4,3,2) (identity property, both unsorted)
unsorted-scale-unsorted: x=(10,30,20), y=(15,5,10) (scale relationship, both unsorted)
unsorted-asymmetric-5-10: x=(2,5,1,3,4), y=(10,5,2,8,4,1,9,3,7,6) (asymmetric sizes, both unsorted)
unsorted-duplicates: x=(3,3,3,3,3), y=(5,5,5,5,5) (all duplicates, any order)
unsorted-mixed-duplicates-x: x=(2,1,3,2,1), y=(1,1,2,2,3) (X has unsorted duplicates)
unsorted-mixed-duplicates-y: x=(1,1,2,2,3), y=(3,2,1,3,2) (Y has unsorted duplicates)
These unsorted tests are critical because RatioBounds computes bounds from pairwise ratios, requiring both samples to be sorted independently. The variety ensures implementations dont incorrectly assume pre-sorted input or sort samples together. Each test must produce identical output to its sorted counterpart, validating that the implementation correctly handles the sorting step.
Error cases — input validation (2 tests):
error-empty-x: x=(), y=(1,2,3,4,5) — empty X array violates validity
error-empty-y: x=(1,2,3,4,5), y=() — empty Y array violates validity
No performance test — RatioBounds uses the FastRatio algorithm internally, which delegates to FastShift in log-space. Since bounds computation involves only two quantile calculations from the pairwise differences (at positions determined by PairwiseMargin), the performance characteristics are equivalent to computing two Ratio estimates, which completes efficiently for large samples.