Center
Robust measure of location (central tendency).
Input
- — input sample of measurements
Output
- Value — estimation of the median of the average of two random measurements from
- Unit — same unit as
Notes
- Also known as — Hodges-Lehmann estimator, pseudomedian
- Complexity —
Properties
- Shift equivariance
- Scale equivariance
Example
Center([0, 2, 4, 6, 8]) = 4Center(x + 10) = 14Center(3x) = 12
is the recommended default for representing where the data is. It works like the familiar mean but does not break when the data contains a few bad measurements or outliers. Up to 29% of data can be corrupted before becomes unreliable. When data is clean, is nearly as precise as the mean (95% efficiency), so the added protection comes at almost no cost. When uncertain whether to use mean, median, or something else, start with .
Algorithm
The estimator computes the median of all pairwise averages from a sample. Given a dataset , this estimator is defined as:
A direct implementation would generate all pairwise averages and sort them. With , this approach creates approximately 50 million values, requiring quadratic memory and time.
The breakthrough came in 1984 when John Monahan developed an algorithm that reduces expected complexity to while using only linear memory (see Monahan 1984). The algorithm exploits the inherent structure in pairwise sums rather than computing them explicitly. After sorting the values , the algorithm considers the implicit upper triangular matrix where for . This matrix has a crucial property: each row and column is sorted in non-decreasing order, enabling efficient median selection without storing the matrix.
Rather than sorting all pairwise sums, the algorithm uses a selection approach similar to quickselect. It maintains search bounds for each matrix row and iteratively narrows the search space. For each row , the algorithm tracks active column indices from to , defining which pairwise sums remain candidates for the median. It selects a candidate sum as a pivot using randomized selection from active matrix elements, then counts how many pairwise sums fall below the pivot. Because both rows and columns are sorted, this counting takes only time using a two-pointer sweep from the matrixs upper-right corner.
The median corresponds to rank where . If fewer than sums lie below the pivot, the median must be larger; if more than sums lie below the pivot, the median must be smaller. Based on this comparison, the algorithm eliminates portions of each row that cannot contain the median, shrinking the active search space while preserving the true median.
Real data often contain repeated values, which can cause the selection process to stall. When the algorithm detects no progress between iterations, it switches to a midrange strategy: find the smallest and largest pairwise sums still in the search space, then use their average as the next pivot. If the minimum equals the maximum, all remaining candidates are identical and the algorithm terminates. This tie-breaking mechanism ensures reliable convergence with discrete or duplicated data.
The algorithm achieves time complexity through linear partitioning (each pivot evaluation requires only operations) and logarithmic iterations (randomized pivot selection leads to expected iterations, similar to quickselect). The algorithm maintains only row bounds and counters, using additional space. This matches the complexity of sorting a single array while avoiding the quadratic memory and time explosion of computing all pairwise combinations.
namespace Pragmastat.Algorithms;
internal static class FastCenter
{
/// <summary>
/// ACM Algorithm 616: fast computation of the Hodges-Lehmann location estimator
/// </summary>
/// <remarks>
/// Computes the median of all pairwise averages (xi + xj)/2 efficiently.
/// See: John F Monahan, "Algorithm 616: fast computation of the Hodges-Lehmann location estimator"
/// (1984) DOI: 10.1145/1271.319414
/// </remarks>
/// <param name="values">A sorted sample of values</param>
/// <param name="random">Random number generator</param>
/// <param name="isSorted">If values are sorted</param>
/// <returns>Exact center value (Hodges-Lehmann estimator)</returns>
public static double Estimate(IReadOnlyList<double> values, Random? random = null, bool isSorted = false)
{
int n = values.Count;
if (n == 1) return values[0];
if (n == 2) return (values[0] + values[1]) / 2;
random ??= new Random();
if (!isSorted)
values = values.OrderBy(x => x).ToList();
// Calculate target median rank(s) among all pairwise sums
long totalPairs = (long)n * (n + 1) / 2;
long medianRankLow = (totalPairs + 1) / 2; // For odd totalPairs, this is the median
long medianRankHigh =
(totalPairs + 2) / 2; // For even totalPairs, average of ranks medianRankLow and medianRankHigh
// Initialize search bounds for each row in the implicit matrix
long[] leftBounds = new long[n];
long[] rightBounds = new long[n];
long[] partitionCounts = new long[n];
for (int i = 0; i < n; i++)
{
leftBounds[i] = i + 1; // Row i can pair with columns [i+1..n] (1-based indexing)
rightBounds[i] = n; // Initially, all columns are available
}
// Start with a good pivot: sum of middle elements (handles both odd and even n)
double pivot = values[(n - 1) / 2] + values[n / 2];
long activeSetSize = totalPairs;
long previousCount = 0;
while (true)
{
// === PARTITION STEP ===
// Count pairwise sums less than current pivot
long countBelowPivot = 0;
long currentColumn = n;
for (int row = 1; row <= n; row++)
{
partitionCounts[row - 1] = 0;
// Move left from current column until we find sums < pivot
// This exploits the sorted nature of the matrix
while (currentColumn >= row && values[row - 1] + values[(int)currentColumn - 1] >= pivot)
currentColumn--;
// Count elements in this row that are < pivot
if (currentColumn >= row)
{
long elementsBelow = currentColumn - row + 1;
partitionCounts[row - 1] = elementsBelow;
countBelowPivot += elementsBelow;
}
}
// === CONVERGENCE CHECK ===
// If no progress, we have ties - break them using midrange strategy
if (countBelowPivot == previousCount)
{
double minActiveSum = double.MaxValue;
double maxActiveSum = double.MinValue;
// Find the range of sums still in the active search space
for (int i = 0; i < n; i++)
{
if (leftBounds[i] > rightBounds[i]) continue; // Skip empty rows
double rowValue = values[i];
double smallestInRow = values[(int)leftBounds[i] - 1] + rowValue;
double largestInRow = values[(int)rightBounds[i] - 1] + rowValue;
minActiveSum = Min(minActiveSum, smallestInRow);
maxActiveSum = Max(maxActiveSum, largestInRow);
}
pivot = (minActiveSum + maxActiveSum) / 2;
if (pivot <= minActiveSum || pivot > maxActiveSum) pivot = maxActiveSum;
// If all remaining values are identical, we're done
if (minActiveSum == maxActiveSum || activeSetSize <= 2)
return pivot / 2;
continue;
}
// === TARGET CHECK ===
// Check if we've found the median rank(s)
bool atTargetRank = countBelowPivot == medianRankLow || countBelowPivot == medianRankHigh - 1;
if (atTargetRank)
{
// Find the boundary values: largest < pivot and smallest >= pivot
double largestBelowPivot = double.MinValue;
double smallestAtOrAbovePivot = double.MaxValue;
for (int i = 1; i <= n; i++)
{
long countInRow = partitionCounts[i - 1];
double rowValue = values[i - 1];
long totalInRow = n - i + 1;
// Find largest sum in this row that's < pivot
if (countInRow > 0)
{
long lastBelowIndex = i + countInRow - 1;
double lastBelowValue = rowValue + values[(int)lastBelowIndex - 1];
largestBelowPivot = Max(largestBelowPivot, lastBelowValue);
}
// Find smallest sum in this row that's >= pivot
if (countInRow < totalInRow)
{
long firstAtOrAboveIndex = i + countInRow;
double firstAtOrAboveValue = rowValue + values[(int)firstAtOrAboveIndex - 1];
smallestAtOrAbovePivot = Min(smallestAtOrAbovePivot, firstAtOrAboveValue);
}
}
// Calculate final result based on whether we have odd or even number of pairs
if (medianRankLow < medianRankHigh)
{
// Even total: average the two middle values
return (smallestAtOrAbovePivot + largestBelowPivot) / 4;
}
else
{
// Odd total: return the single middle value
bool needLargest = countBelowPivot == medianRankLow;
return (needLargest ? largestBelowPivot : smallestAtOrAbovePivot) / 2;
}
}
// === UPDATE BOUNDS ===
// Narrow the search space based on partition result
if (countBelowPivot < medianRankLow)
{
// Too few values below pivot - eliminate smaller values, search higher
for (int i = 0; i < n; i++)
leftBounds[i] = i + partitionCounts[i] + 1;
}
else
{
// Too many values below pivot - eliminate larger values, search lower
for (int i = 0; i < n; i++)
rightBounds[i] = i + partitionCounts[i];
}
// === PREPARE NEXT ITERATION ===
previousCount = countBelowPivot;
// Recalculate how many elements remain in the active search space
activeSetSize = 0;
for (int i = 0; i < n; i++)
{
long rowSize = rightBounds[i] - leftBounds[i] + 1;
activeSetSize += Max(0, rowSize);
}
// Choose next pivot based on remaining active set size
if (activeSetSize > 2)
{
// Use randomized row median strategy for efficiency
// Handle large activeSetSize by using double precision for random selection
double randomFraction = random.NextDouble();
long targetIndex = (long)(randomFraction * activeSetSize);
int selectedRow = 0;
// Find which row contains the target index
long cumulativeSize = 0;
for (int i = 0; i < n; i++)
{
long rowSize = Max(0, rightBounds[i] - leftBounds[i] + 1);
if (targetIndex < cumulativeSize + rowSize)
{
selectedRow = i;
break;
}
cumulativeSize += rowSize;
}
// Use median element of the selected row as pivot
long medianColumnInRow = (leftBounds[selectedRow] + rightBounds[selectedRow]) / 2;
pivot = values[selectedRow] + values[(int)medianColumnInRow - 1];
}
else
{
// Few elements remain - use midrange strategy
double minRemainingSum = double.MaxValue;
double maxRemainingSum = double.MinValue;
for (int i = 0; i < n; i++)
{
if (leftBounds[i] > rightBounds[i]) continue; // Skip empty rows
double rowValue = values[i];
double minInRow = values[(int)leftBounds[i] - 1] + rowValue;
double maxInRow = values[(int)rightBounds[i] - 1] + rowValue;
minRemainingSum = Min(minRemainingSum, minInRow);
maxRemainingSum = Max(maxRemainingSum, maxInRow);
}
pivot = (minRemainingSum + maxRemainingSum) / 2;
if (pivot <= minRemainingSum || pivot > maxRemainingSum)
pivot = maxRemainingSum;
if (minRemainingSum == maxRemainingSum)
return pivot / 2;
}
}
}
}Notes
This section compares the toolkits robust average estimator against traditional methods to demonstrate its advantages across diverse conditions.
Average Estimators
Mean (arithmetic average):
Median:
Center (Hodges-Lehmann estimator):
Breakdown
Heavy-tailed distributions naturally produce extreme outliers that completely distort traditional estimators. A single extreme measurement from the distribution can make the sample mean arbitrarily large. Real-world data can also contain corrupted measurements from instrument failures, recording errors, or transmission problems. Both natural extremes and data corruption create the same challenge: extracting reliable information when some measurements are too influential.
The breakdown point (Huber 2009) is the fraction of a sample that can be replaced by arbitrarily large values without making an estimator arbitrarily large. The theoretical maximum is ; no estimator can guarantee reliable results when more than half the measurements are extreme or corrupted. In such cases, summary estimators are not applicable, and a more sophisticated approach is needed.
A breakdown point is rarely needed in practice, as more conservative values also cover practical needs. Additionally, a high breakdown point corresponds to low precision (information is lost by neglecting part of the data). The optimal practical breakdown point should be between (no robustness) and (low precision).
The estimator achieves a breakdown point, providing substantial protection against realistic contamination levels while maintaining good precision.
Asymptotic breakdown points for average estimators:
| 0% | 50% | 29% |
Drift
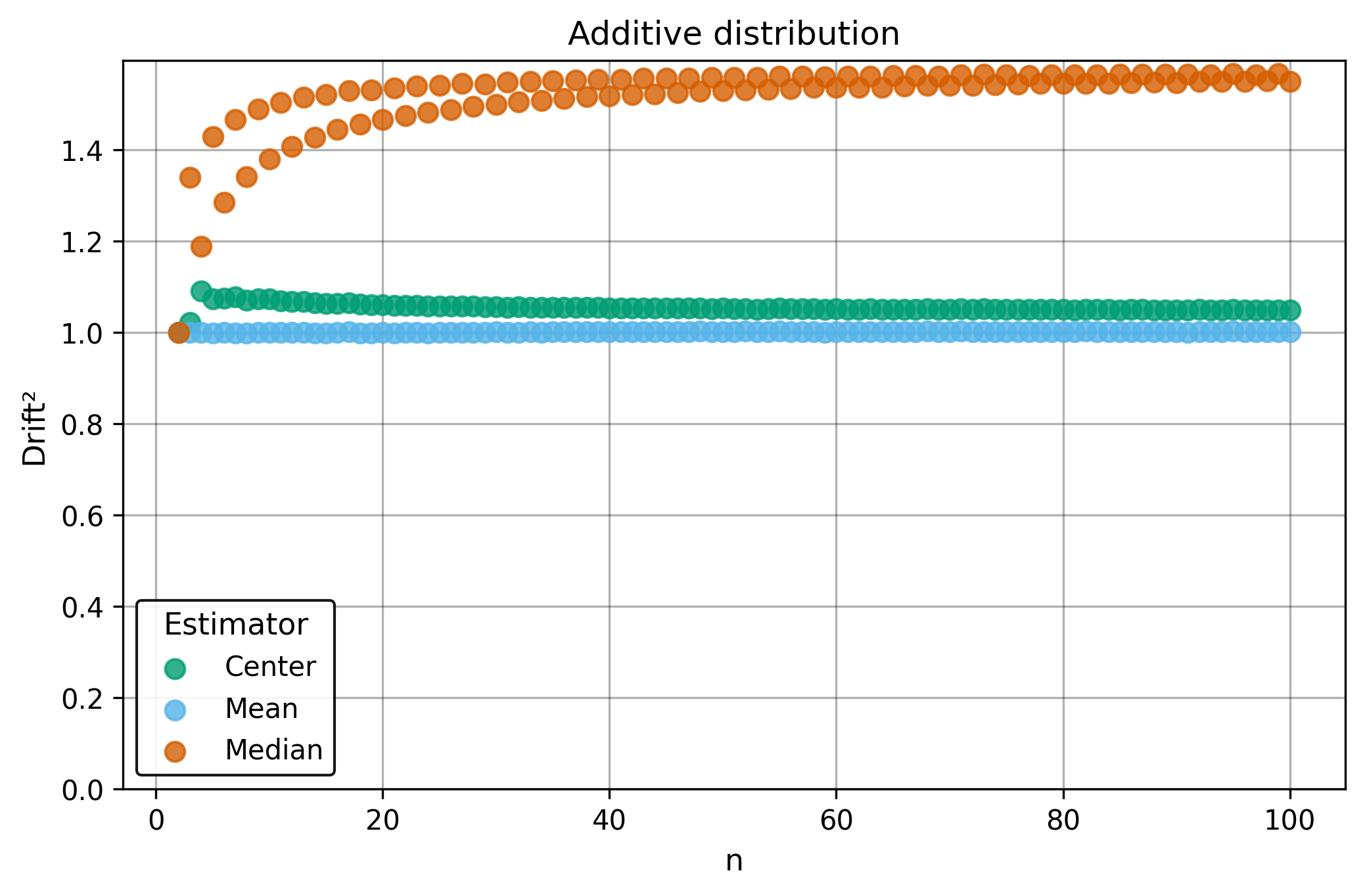
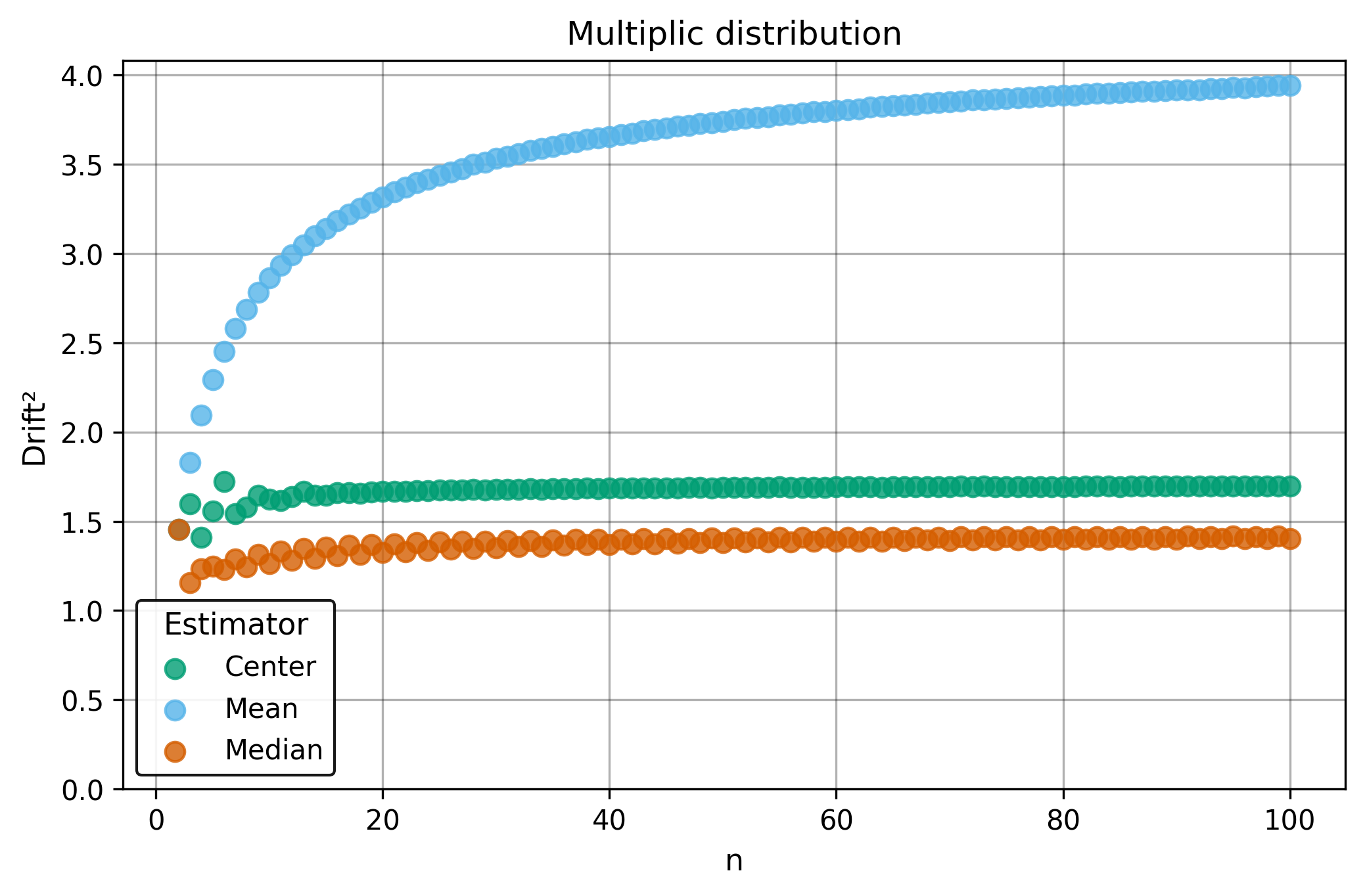
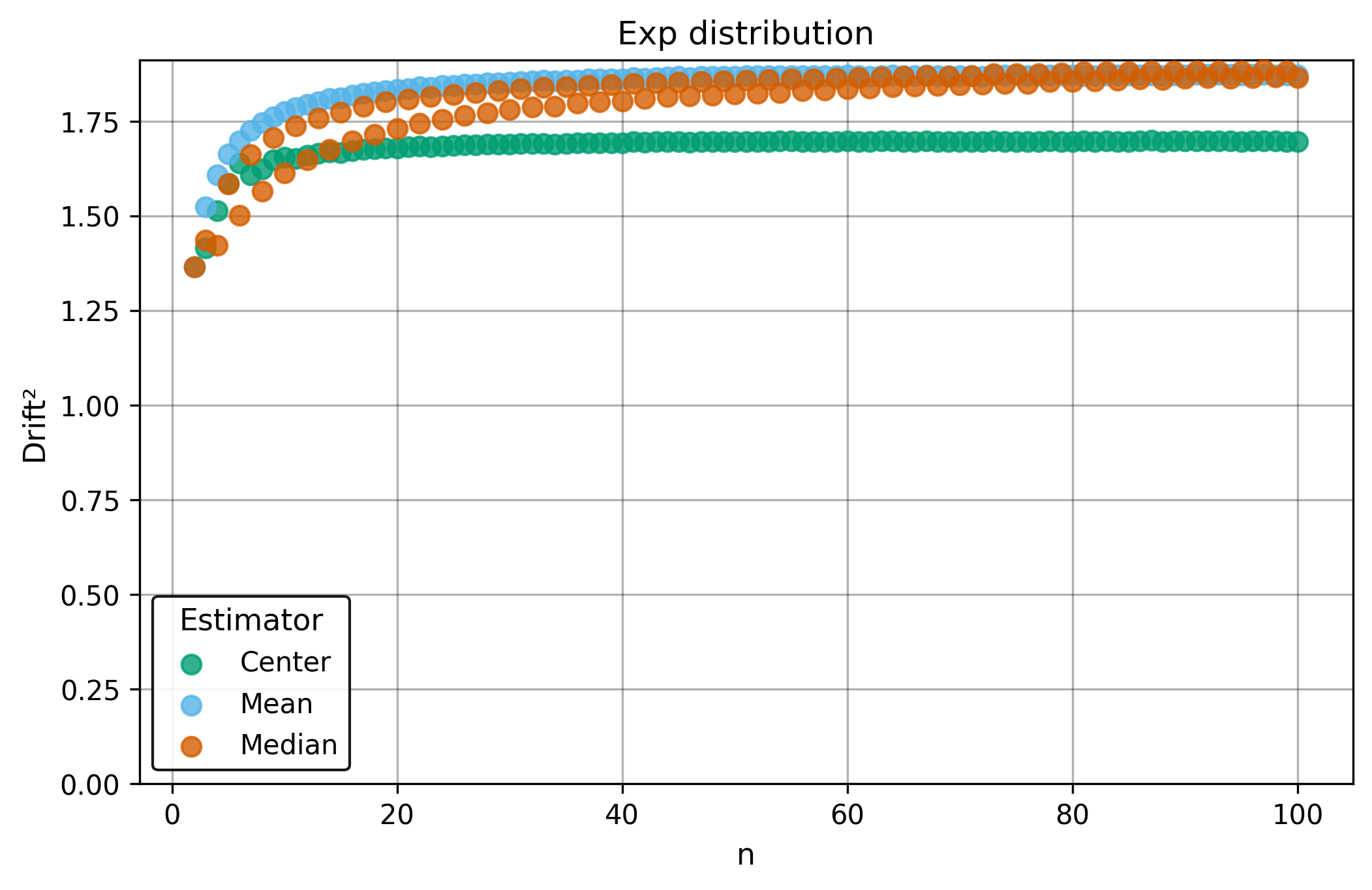
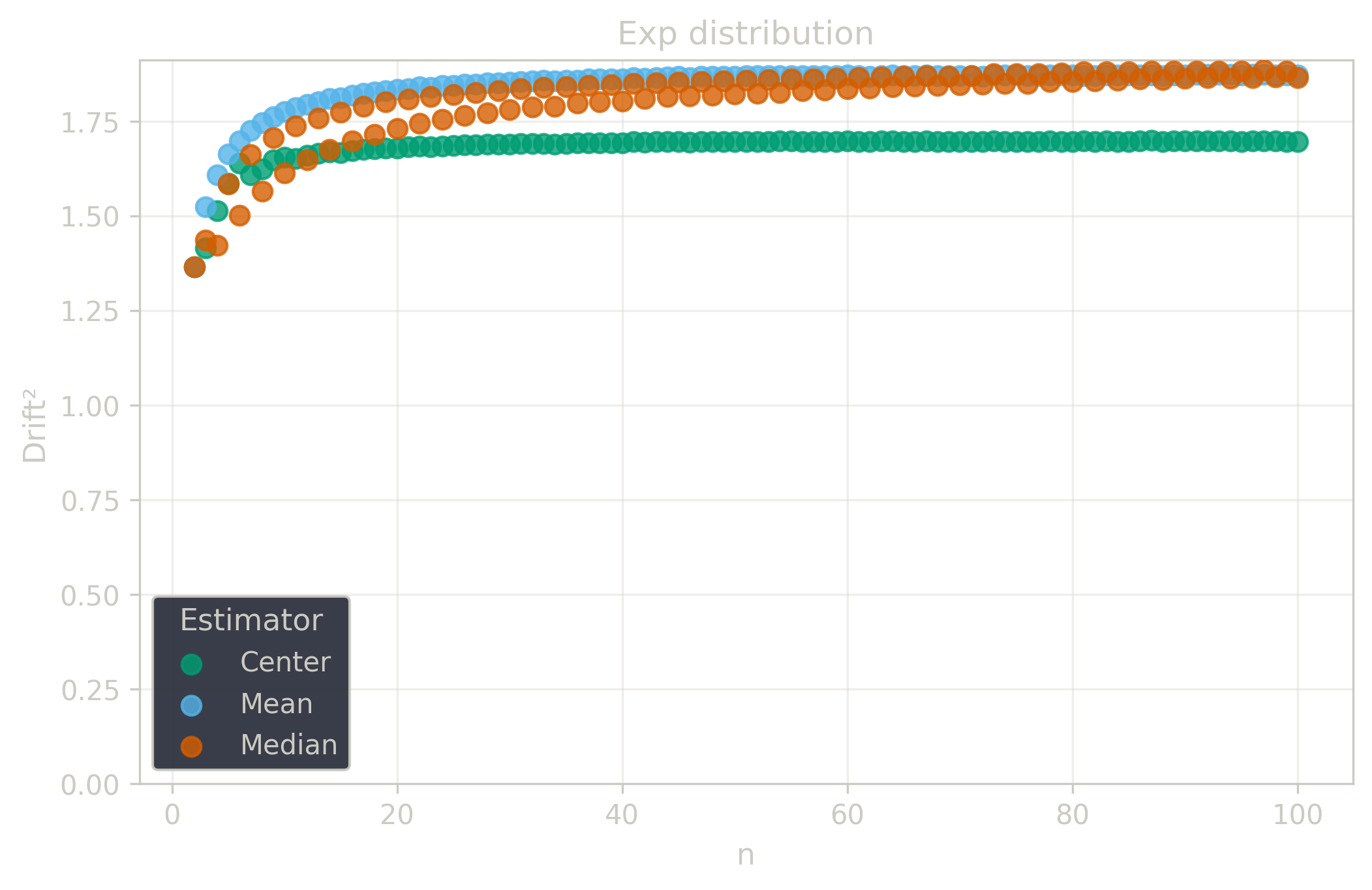
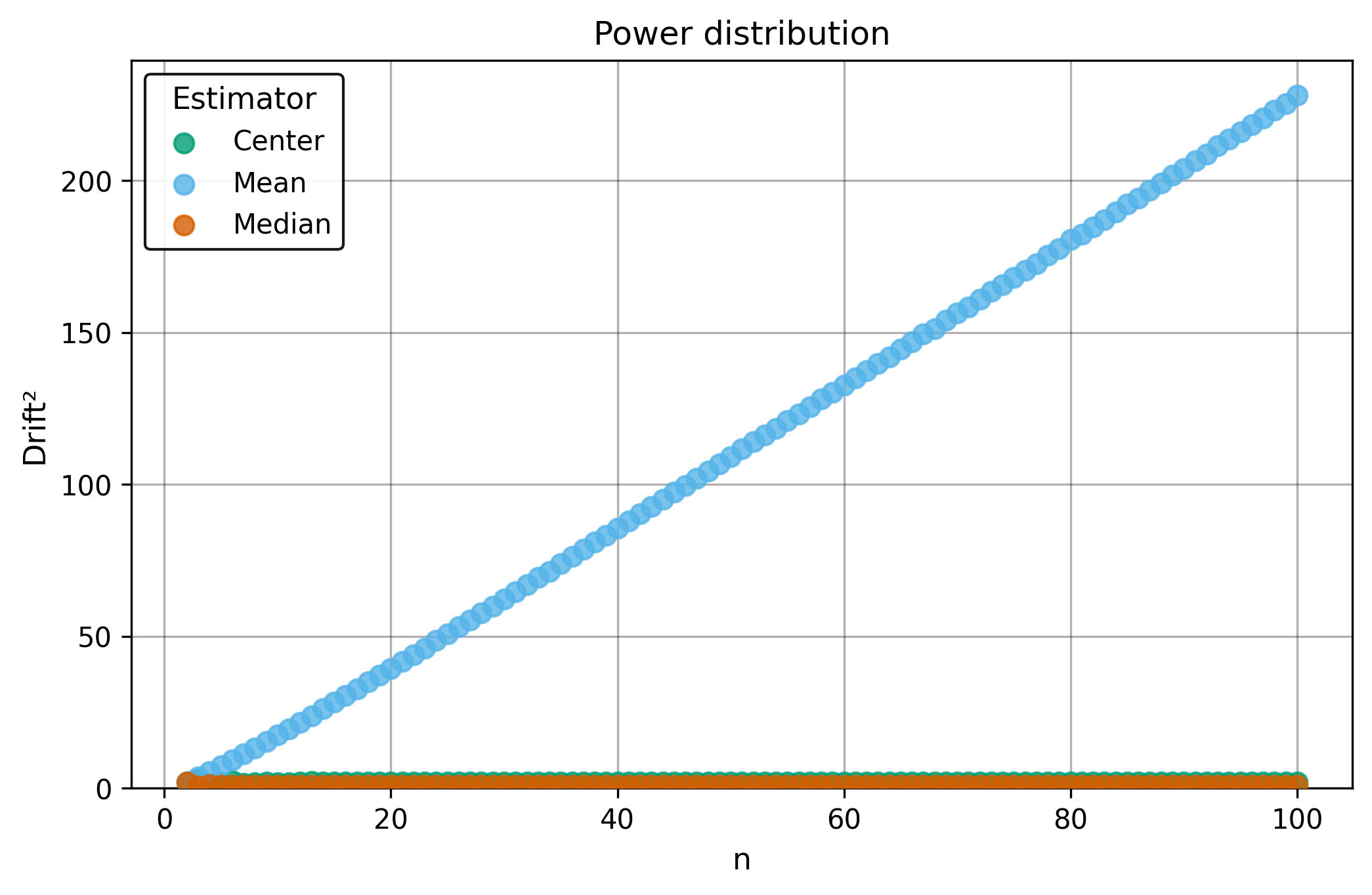
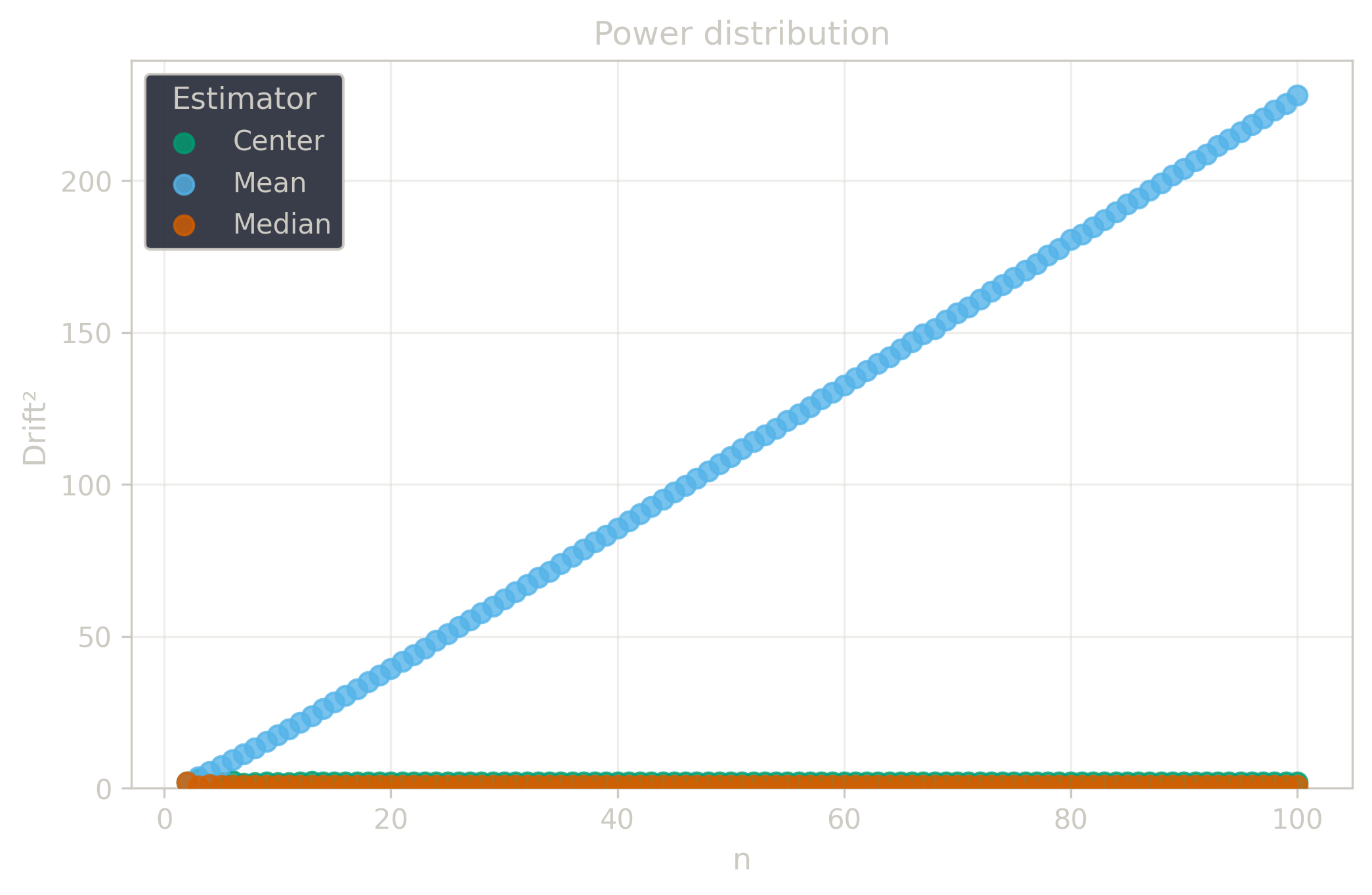
Drift measures estimator precision by quantifying how much estimates scatter across repeated samples. It is based on the of estimates and therefore has a breakdown point of approximately .
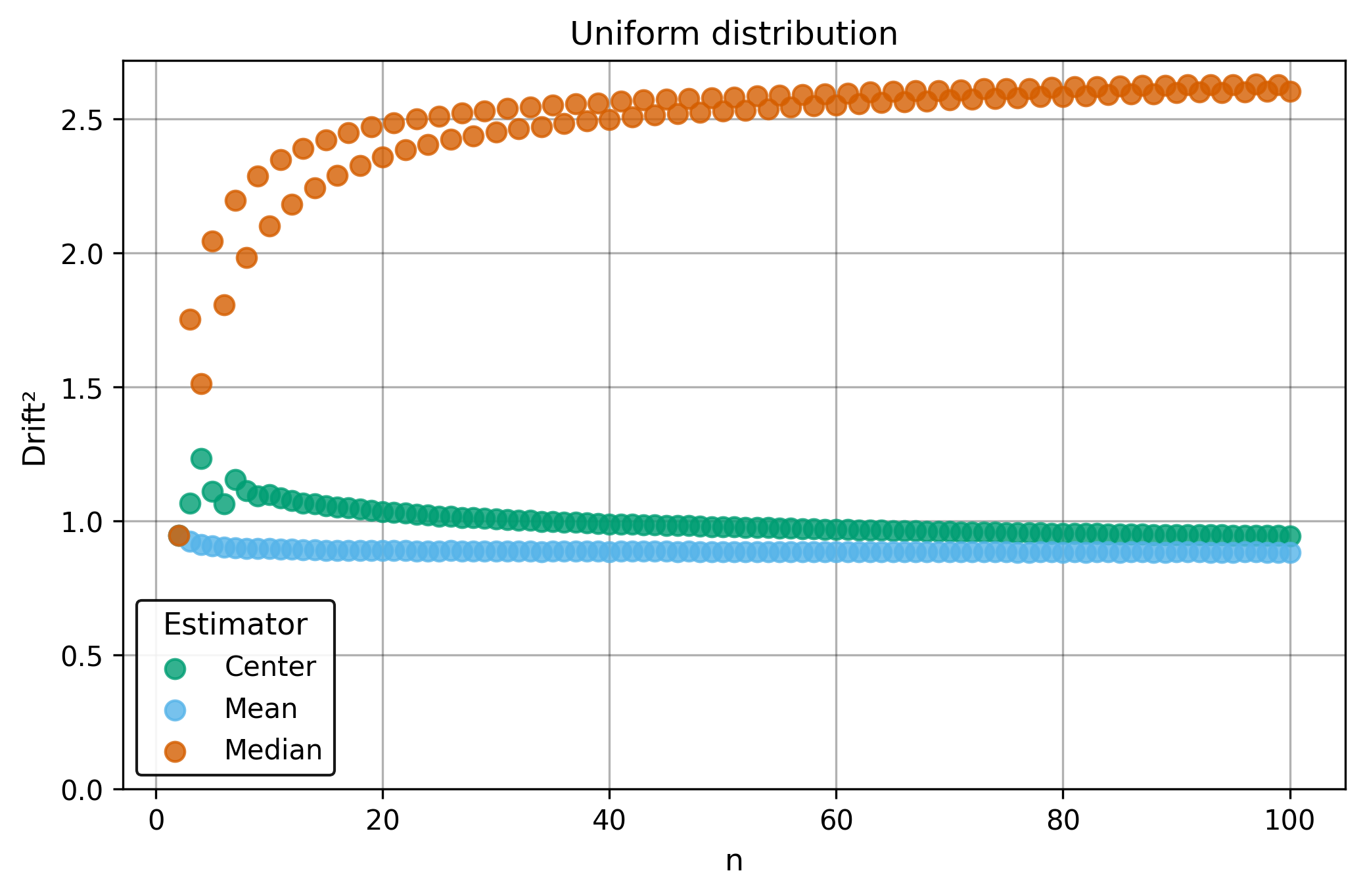
Drift is useful for comparing the precision of several estimators. To simplify the comparison, one of the estimators can be chosen as a baseline. A table of squared drift values, normalized by the baseline, shows the required sample size adjustment factor for switching from the baseline to another estimator. For example, if is the baseline and the rescaled drift square of is , this means that requires times more data than to achieve the same precision. See From Statistical Efficiency to Drift for details.
Squared Asymptotic Drift of Average Estimators (values are approximated):
| 1.0 | 1.571 | 1.047 | |
| 3.95 | 1.40 | 1.7 | |
| 1.88 | 1.88 | 1.69 | |
| 0.9 | 2.1 | ||
| 0.88 | 2.60 | 0.94 |
Rescaled to (sample size adjustment factors):
| 0.96 | 1.50 | 1.0 | |
| 2.32 | 0.82 | 1.0 | |
| 1.11 | 1.11 | 1.0 | |
| 0.43 | 1.0 | ||
| 0.936 | 2.77 | 1.0 |
Tests
The test suite contains 39 test cases stored in the repository (24 original + 14 unsorted + 1 error), plus 1 performance test that should be implemented manually (see Test Framework).
Demo examples () — from manual introduction, validating properties:
demo-1: , expected output: (base case)demo-2: (= demo-1 + 10), expected output: (location equivariance)demo-3: (= 3 × demo-1), expected output: (scale equivariance)
Natural sequences () — canonical happy path examples:
natural-1: , expected output:natural-2: , expected output:natural-3: , expected output:natural-4: , expected output: (smallest even size with rich structure)
Negative values () — sign handling validation:
negative-3: , expected output:
Zero values () — edge case testing with zeros:
zeros-1: , expected output:zeros-2: , expected output:
Additive distribution () — fuzzy testing with :
additive-5,additive-10,additive-30: random samples generated with seed 0
Uniform distribution () — fuzzy testing with :
uniform-5,uniform-100: random samples generated with seed 1
The random samples validate that performs correctly on realistic distributions at various sample sizes. The progression from small () to large () samples helps identify issues that only manifest at specific scales.
Algorithm stress tests — edge cases for fast algorithm implementation:
duplicates-5: (all identical, stress stall handling)duplicates-10: (many duplicates, stress tie-breaking)parity-odd-7: (odd sample size for odd total pairs)parity-even-6: (even sample size for even total pairs)parity-odd-49: 49-element sequence (large odd, 1225 pairs)parity-even-50: 50-element sequence (large even, 1275 pairs)
Extreme values — numerical stability and range tests:
extreme-large-5: (very large values)extreme-small-5: (very small positive values)extreme-wide-5: (wide range, tests precision)
Unsorted tests — verify sorting correctness (14 tests):
unsorted-reverse-{n}for : reverse sorted natural sequences (5 tests)unsorted-shuffle-3: (middle element first)unsorted-shuffle-4: (interleaved)unsorted-shuffle-5: (complex shuffle)unsorted-last-first-5: (last moved to first)unsorted-first-last-5: (first moved to last)unsorted-duplicates-mixed-5: (all identical, any order)unsorted-duplicates-unsorted-10: (duplicates mixed)unsorted-extreme-large-unsorted-5: (large values unsorted)unsorted-parity-odd-reverse-7: (odd size reverse)
These tests ensure implementations correctly sort input data before computing pairwise averages. The variety of shuffle patterns (reverse, rotation, interleaving, single element displacement) catches common sorting bugs.
Error case — input validation:
error-empty-x: — empty array violates validity
Performance test — validates the fast algorithm:
- Input:
- Expected output:
- Time constraint: Must complete in under 5 seconds
- Purpose: Ensures that the implementation uses the efficient algorithm rather than materializing all billion pairwise averages
This test case is not stored in the repository because it generates a large JSON file (approximately 1.5 MB). Each language implementation should manually implement this test with the hardcoded expected result.